Ubuntu Hadoop單節點安裝
建立hadoop用戶
sudo useradd -m <使用者名稱> -s /bin/bash --> 建立使用者
sudo passwd <使用者名稱> --> 變更密碼
sudo adduser <使用者名稱> sudo --> 幫使用者增加管理員權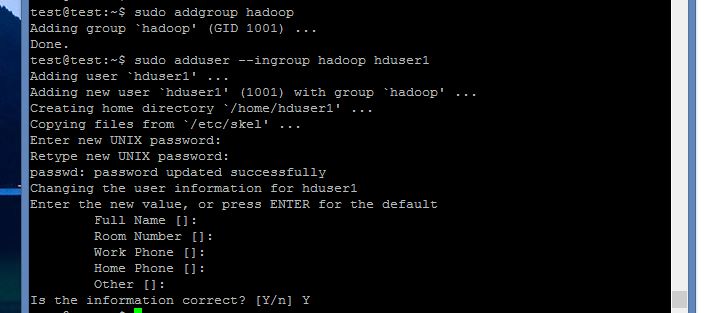](螢幕截圖 2015-12-23 16.21.23.png)限

更新apt
切換至hadoop用戶,更新apt使之後安裝更便利。
安裝Vim,讓修改資料時方便輸入。
sudo apt-get update
sudo apt-get install vim
安裝SSH、配置SSH無密碼登入
執行安裝SSH
sudo apt-get install openssh-server
登入本機
ssh localhost
先登出後進行修改
exit
進入.ssh的資料夾
cd ~/.ssh/
產生金鑰 (全按enter即可)
ssh-keygen -t rsa
加入授權
cat ./id_rsa.pub >> ./authorized_keys
進行測試,是否可以免密碼登入
ssh localhost


安裝java
sudo apt-get install default-jdk
偵測版本
java -version
修改bashrc的文件
vim ~/.bashrc
在最後面貼上
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
source ~/.bashrc



安裝環境
安装 Hadoop
下載Hadoop的壓縮檔,並解壓縮至/usr/local
wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
sudo tar xvzf hadoop-2.6.0.tar.gz -C /usr/local
進入usr/local/中修改
cd /usr/local/
將解壓縮完的資料夾改名為hadoop
sudo mv ./hadoop-2.6.0/ ./hadoop
檢視資料夾權限
ls -l
修改hadoop的權限
sudo chown -R hduser:hduser ./hadoop
cd /usr/local/hadoop
mkdir ./input
實際運行
cp ./etc/hadoop/*.xml ./input
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/*
rm -r ./output
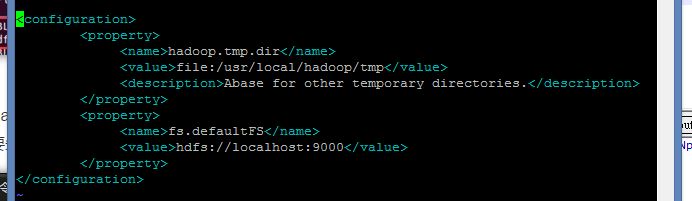
修改core-site.xml文件內容
vim ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

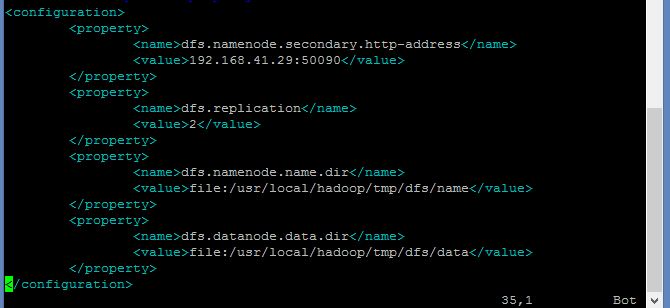
修改hdfs-site.xml文件內容
vim ./etc/hadoop/hdfs-site.xml
<configuration>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

複製mapred-site.xml.template且命名為mapred-site.xml
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
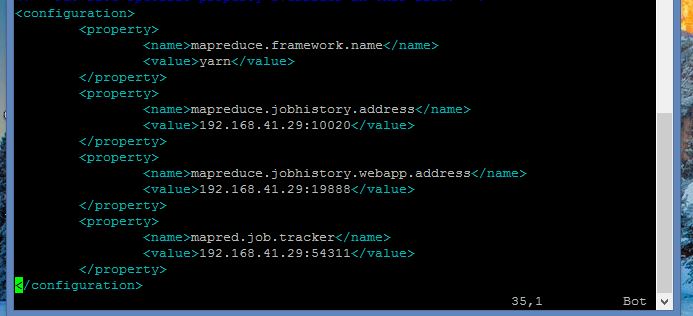
修改mapred-site.xml文件內容
vim ./etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
</configuration>
修改yarn-site.xml文件內容
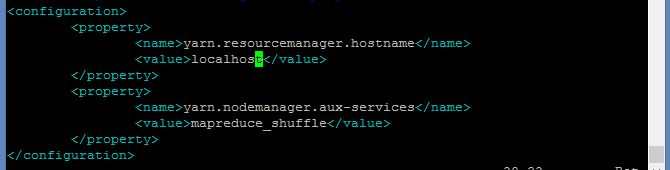
vim ./etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

節點初始化和啟動
hdfs namenode -format
start-all.sh